

Abstract
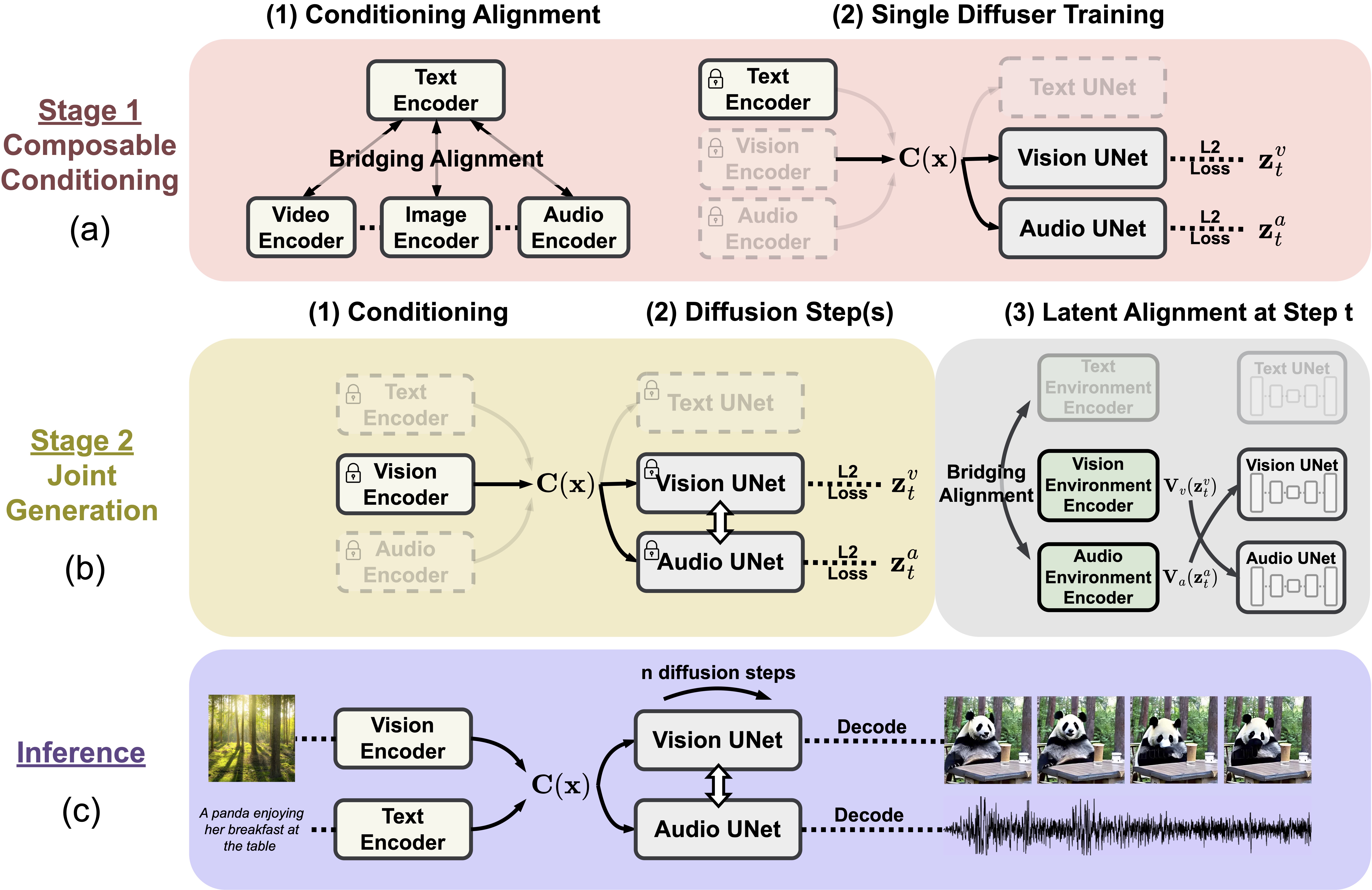
We present Composable Diffusion (CoDi), a novel generative model capable of generating any combination of output modalities, such as language, image, video, or audio, from any combination of input modalities. Unlike existing generative AI systems, CoDi can generate multiple modalities in parallel and its input is not limited to a subset of modalities like text or image. Despite the absence of training datasets for many combinations of modalities, we propose to align modalities in both the input and output space. This allows CoDi to freely condition on any input combination and generate any group of modalities, even if they are not present in the training data. CoDi employs a novel composable generation strategy which involves building a shared multimodal space by bridging alignment in the diffusion process, enabling the synchronized generation of intertwined modalities, such as temporally aligned video and audio. Highly customizable and flexible, CoDi achieves strong joint-modality generation quality, and outperforms or is on par with the unimodal state-of-the-art for single-modality synthesis.
Model Architecture
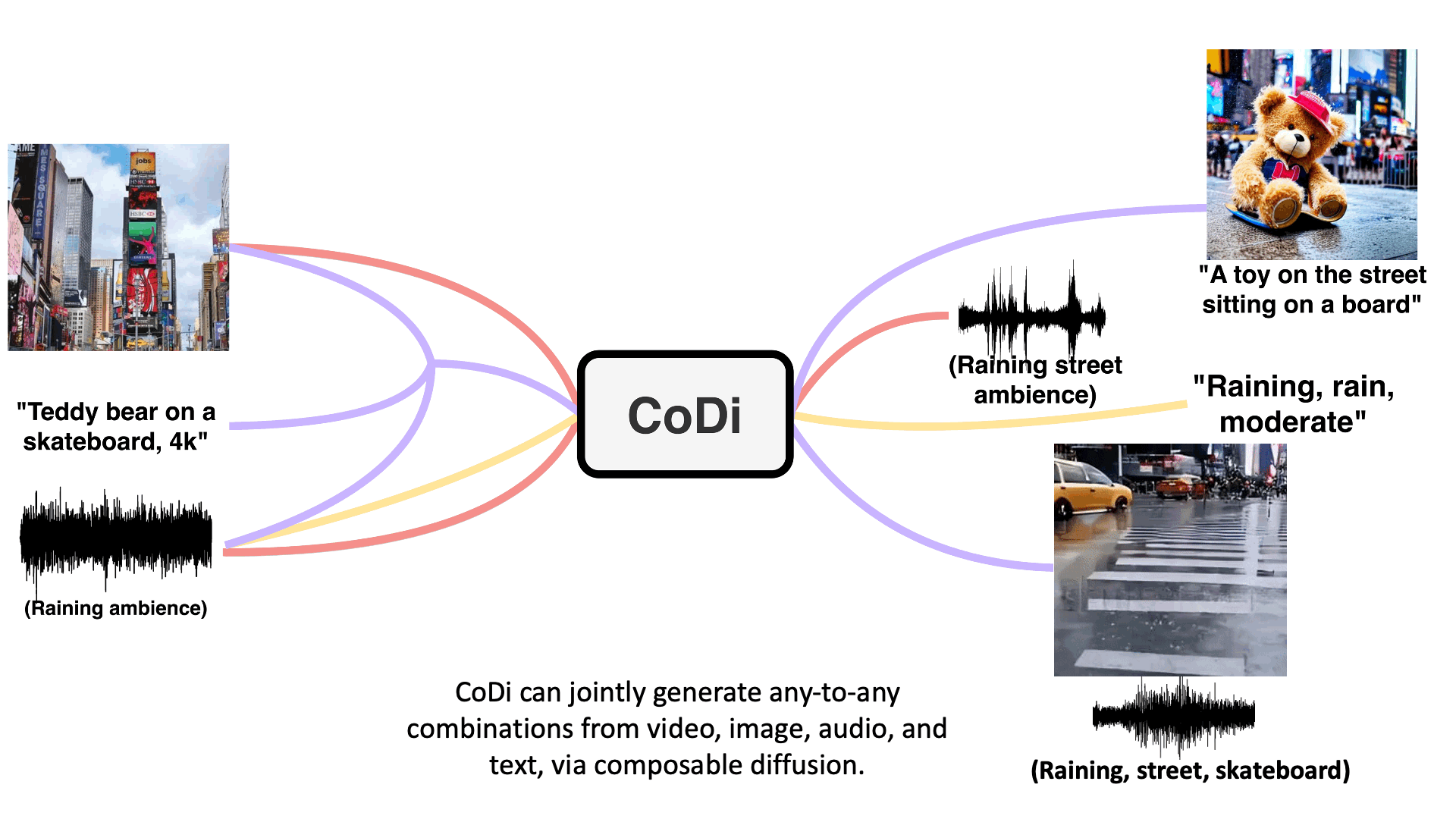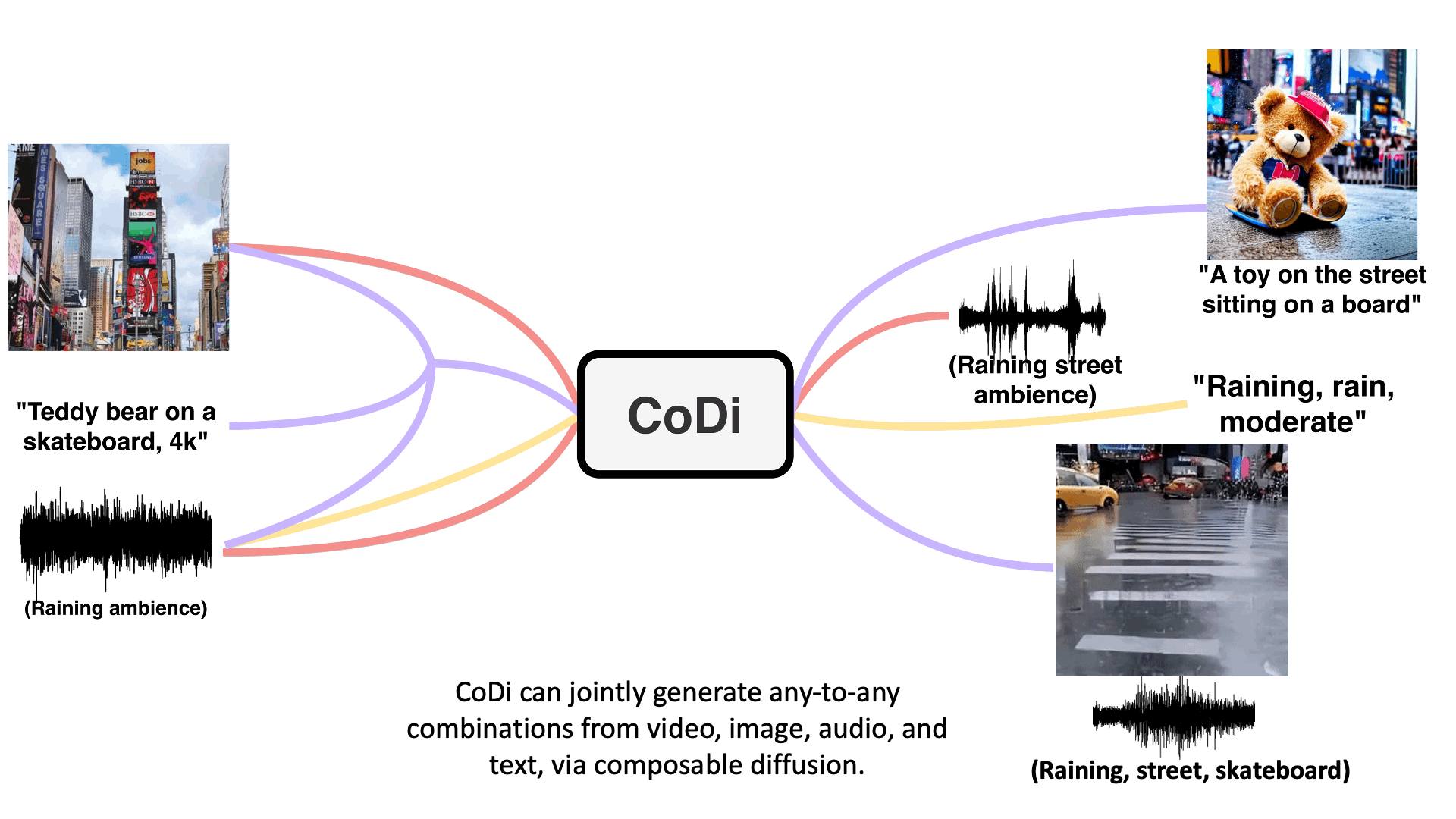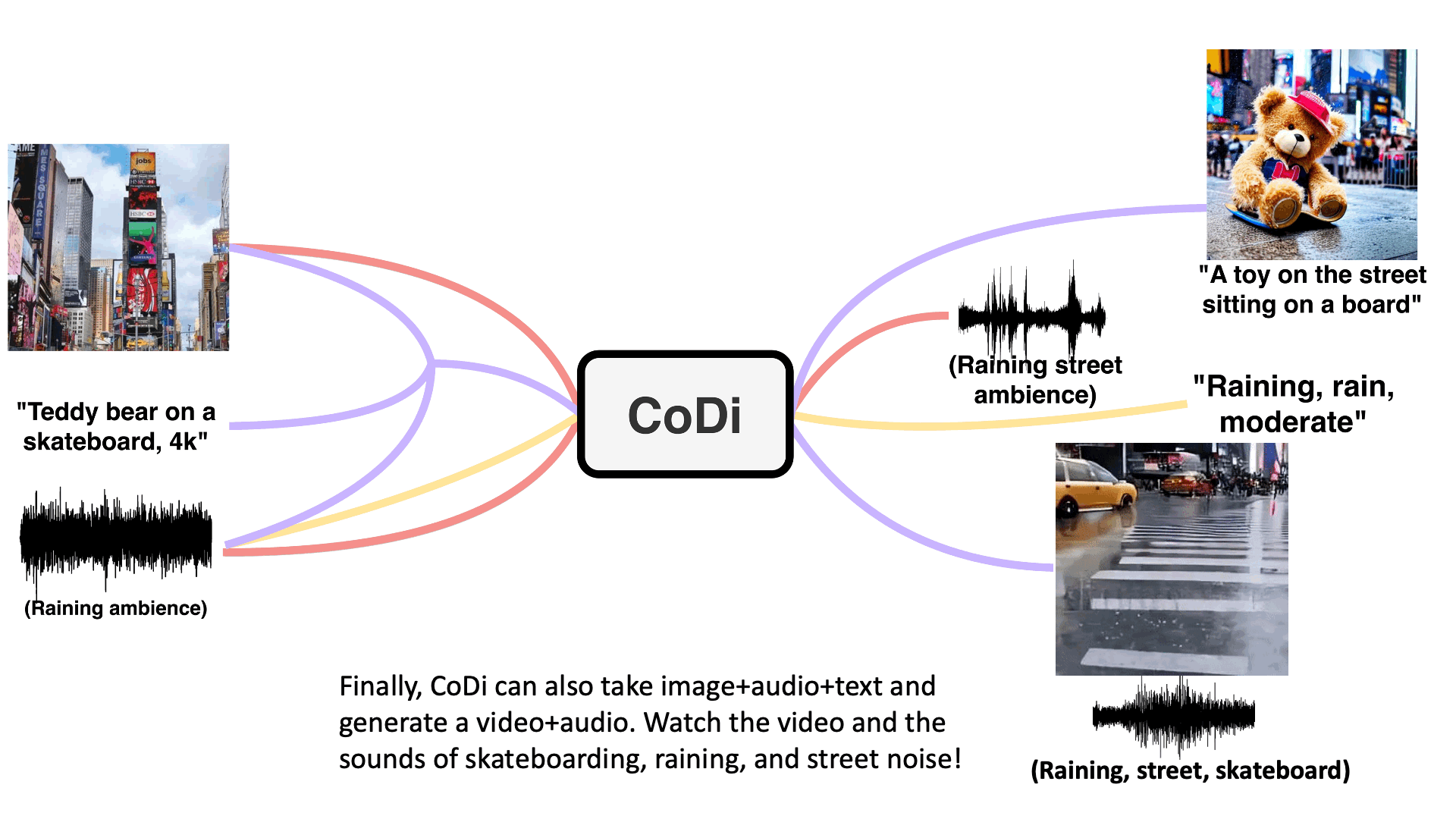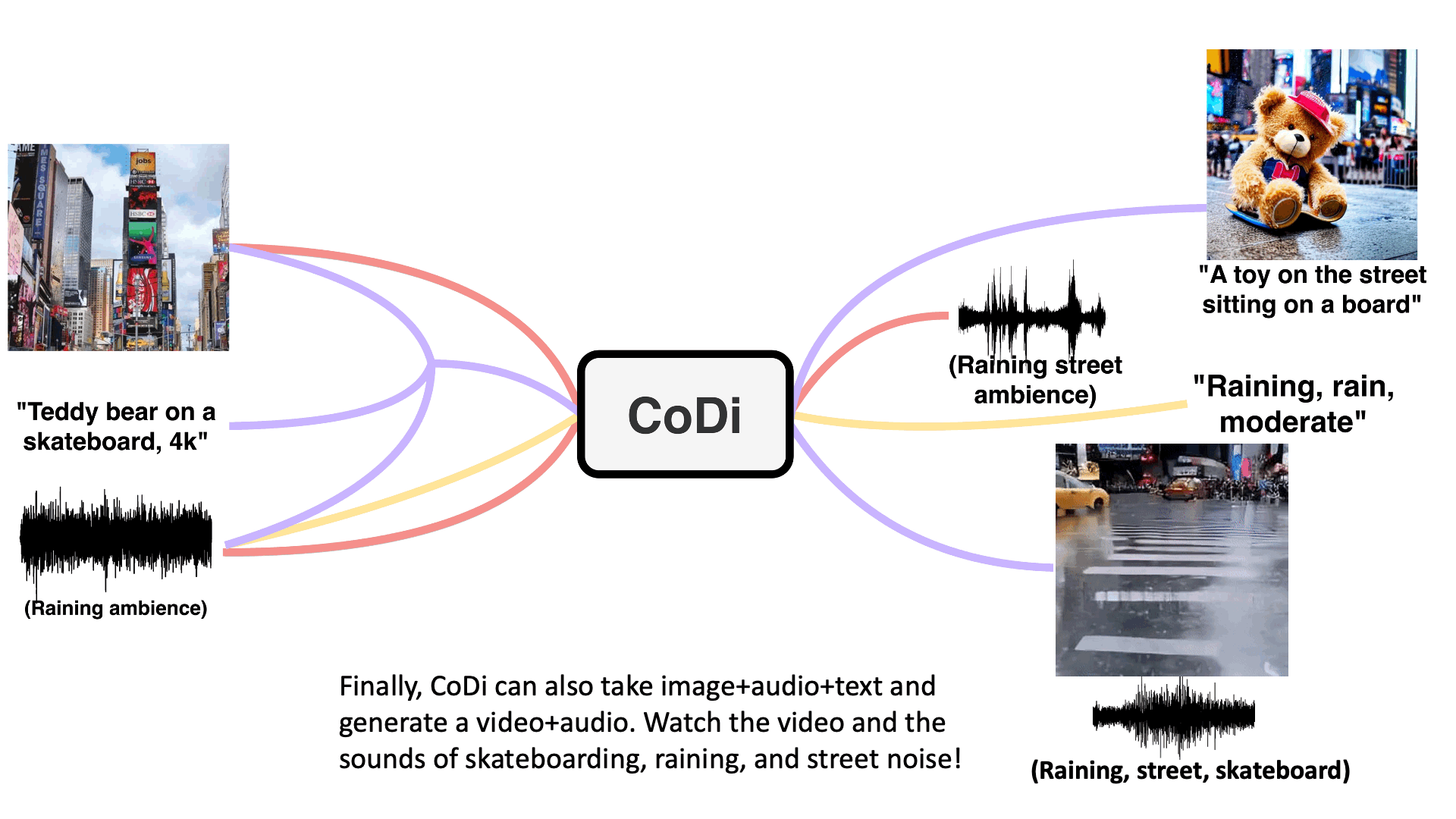
Multi-Outputs Joint Generation
Model takes in single or multiple prompts including video, image, text, or audio to generate multiple aligned outputs like video with accompanying sound.
Text + Image + Audio → Video + Audio
Text + Audio + Image → Text + Image
Audio + Image → Text + Image


Text + Image → Text + Image


Text → Video + Audio
Text → Video + Audio
Text → Video + Audio
Text → Text + Audio + Image

Text → Text + Audio + Image

Multiple Conditioning
Model takes in multiple inputs including video, image, text, or audio to generate outputs.
Text + Audio → Image

Text + Image → Image


Text + Audio → Video

Text + Image → Video


Text + Image → Video


Video + Audio → Text
Image + Audio → Audio

Text + Image → Audio

Single-to-Single Generation
Model takes in a single prompt including video, image, text, or audio to generate a single output.
Text → Image

Audio → Image

Image → Video


Image → Audio

Audio → Text
Image → Text

BibTeX
@inproceedings{
tang2023anytoany,
title={Any-to-Any Generation via Composable Diffusion},
author={Zineng Tang and Ziyi Yang and Chenguang Zhu and Michael Zeng and Mohit Bansal},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=2EDqbSCnmF}
}